
分析师/玲玲
校对/Tina
策划/Eason
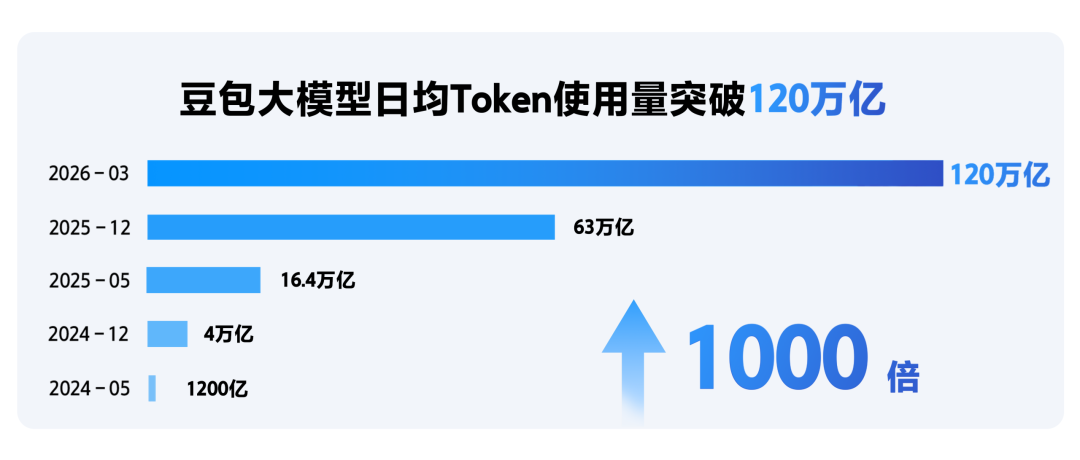
今天,在火山引擎举办的“2026 Force Link AI 创新巡展-武汉站”上,火山引擎总裁谭待披露了一个关键数据:豆包大模型日均Token使用量已突破120万亿。三个月时间内翻了一倍,相较两年前的数据实现了1000倍的高速增长。
同日,OpenClaw的ClawHub中国镜像站正式上线。为这个镜像站提供基础设施支持的,正是火山引擎。
120万亿Token意味着什么?简单换算——如果每个Token对应一个中文字符,120万亿Token相当于每天有2400亿本《红楼梦》的文字量在豆包系统中流转。更直观的对比是,这相当于ChatGPT巅峰时期全球日调用量的2-3倍。
放眼全球,此前日Token消耗超过100万亿的,只有OpenAI和Google两家。火山引擎成为第三家迈入这个俱乐部的玩家。
对于这一里程碑式的增长,火山引擎总裁谭待给出了清晰的解读。他指出,Token使用量是衡量AI发展速度的核心指标,而近期豆包大模型使用量的高速增长,主要归因于两大引擎:AI视频创作的爆发与AI智能体的加速普及。
首先是AI视频创作的全面爆发。 从文本到音频再到视频,Token的消耗量呈现出指数级跃迁。一段几十字的聊天对话仅消耗几十个Token;一段数分钟的语音,维度更丰富;而一秒钟的高清视频生成,其背后涉及的Token数量可以轻松突破百万。今年春节前后,豆包旗下的Seedance 2.0视频模型在社交网络刷屏,大量创作者涌入即梦和豆包平台,直接拉动了视频类Token调用曲线的陡峭攀升。
其次是AI智能体的加速普及。 2026年被视为AI Agent的商用元年,而Token正是智能体执行任务的“燃料”。一个复杂的Agent任务——从理解用户模糊指令、拆解步骤,到调用工具、多轮修正——背后是动辄数万甚至数十万Token的消耗。
一个标志性事件是:开源智能体框架OpenClaw(俗称“龙虾”)的中国镜像站今日正式上线,由火山引擎赞助基础设施。

该镜像站为国内开发者提供了经过安全扫描的Skill(技能)库,支持一键安装。这意味着,国内开发者可以更顺畅地获取智能体的“手脚”——各种功能插件。每安装一个Skill、每调用一次工具,背后都是Token在燃烧。Skill生态越繁荣,Token消耗越旺盛,二者形成了正向加速循环。
在这两大引擎的驱动下,豆包的用户版图也在持续扩张。
C端方面,豆包App已拥有近7800万日活跃用户,总下载量超过8500万次;B端方面,豆包能力通过火山引擎API源源不断输送给数以万计的企业和开发者,覆盖电商、金融、教育、汽车等多元场景。

开发者也凭借豆包2.0 Pro每百万Token输入3.2元、输出16元的极致成本优势,以极低门槛探索AI应用边界,进一步推高了调用量。
在豆包DAU破亿时,业内曾有一种声音:“不过是靠抖音的流量灌入”。但日均120万亿Token的含金量,远非“流量扶持”所能解释。
豆包的崛起路径,展现了一套与传统大模型截然不同的“场景生态”打法:
第一层:产品矩阵协同
豆包从未以孤立的“对话机器人”形态存在。它深度集成在飞书(办公)、剪映(视频创作)、醒图(图片处理)、抖音(内容分发)等字节系产品中。用户在剪映里点击“智能生成字幕”,调用的就是豆包的语音识别能力;在飞书文档里输入“/”,弹出的AI写作助手背后同样是豆包。
“这种深度集成让用户感知不到‘我在用一个大模型’,只觉得‘这个功能很好用’。”一位接近豆包团队的人士透露,“我们内部不提‘DAU’,更关注‘场景渗透率’——有多少工作环节被AI自然替代了。”
第二层:企业端“润物细无声”
当其他大模型厂商还在为拿下“第一个百万合同”举办发布会时,豆包已经通过飞书生态进入了数十万家企业的日常工作流。
“我们公司采购飞书时,豆包功能是默认开启的。”上海一家跨境电商公司的CTO表示,“起初大家只是用来自动写会议纪要,后来发现它能关联历史文档、理解业务术语,现在连海外营销文案、客服话术模板都交给它生成。”
这种“捆绑销售”看似被动,实则高效——企业为办公协作工具付费时,AI能力成了“免费增值服务”,使用门槛几乎为零。
第三层:开发者生态的“反哺循环”
2026年1月上线的“扣子2.0”低代码开发平台,让普通用户也能基于豆包的能力创建自定义AI技能(Skill)。截至目前,扣子平台已有超过200万个用户创建的Skill,其中日均调用量超过1000次的“热门Skill”达3.7万个,这种模式让非技术背景的人也能参与AI生态。
这些Skill反过来又丰富了豆包的能力边界——用户调用Skill时,Token消耗计入豆包总使用量,形成正向循环。
尽管“龙虾”热度高涨,token使用量激增,谭待却在武汉分享了他们的冷静观察:大量企业实践下来,“养虾”(部署智能体)仍然卡在三个关键环节——模型能力、Skill生态、安全管控。
关卡一:模型能力是大脑
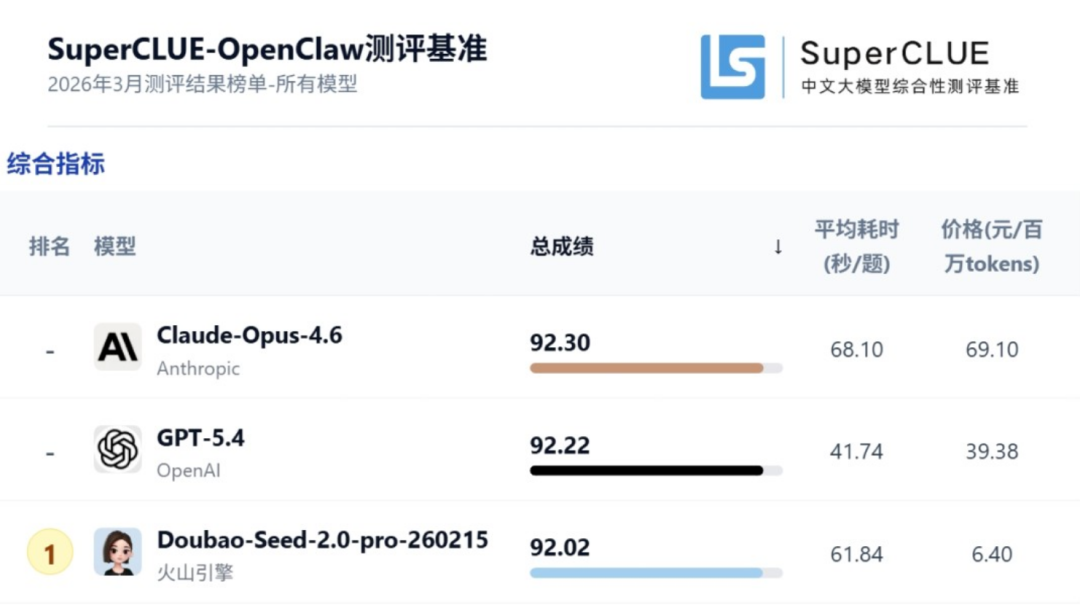
今年2月,豆包大模型2.0系列发布,在多模态理解和智能体能力上均有明显提升。在国内权威测评机构SuperCLUE针对“智能体”场景的专项评测中,豆包2.0 Pro综合能力排名国内第一,仅次于Claude Opus 4.6和GPT‑5.4,被认为是最适合“养虾”的中文模型。
关卡二:Skills生态是手脚
光有模型提供“大脑”并不够,智能体还得能真正“干活”。Skill生态的广度和深度,直接决定了智能体的能力上限。这也是OpenClaw中国镜像站的意义所在——让国内开发者能够顺畅地获取和安装各种技能插件。截至目前,扣子平台上的Skill数量已突破200万,但与全球智能体生态的需求相比,仍有巨大空间。
关卡三:安全是底线
智能体权限越大,风险越大。员工私装智能体实例、插件来源不明、工具调用权限失控……这些问题已经在企业里陆续出现。
火山引擎是国内最早发布智能体安全方案的云厂商之一。春节前,其智能体安全方案已经上线;近期,这套方案通过了中国信通院的两项权威安全认证:一是“智能助理智能体产品可信能力认证”,考察平台的安全架构和管控能力;二是“安全防护产品有效性认证”,考察真实攻击场景下的防护成功率。
目前国内同时拿到这两项认证的,只有火山引擎一家。
回望过去三年,大模型厂商的发布会总在强调几个数字:参数规模(千亿/万亿)、上下文长度(128K/1M)、基准测试得分(MMLU、C-Eval)。但到了2026年,投资人问的第一个问题变成了:“你的模型,每天真正被用多少次?”
“技术领先性当然重要,但如果不能转化为稳定的用户需求和收入增长,万亿参数也只是昂贵的计算实验。”一位专注AI赛道的一级市场投资人如此评价。
这种转变的背后,是资本市场的理性回归。当单一模型的调用量达到百万亿级规模,接下来的竞争将围绕“应用生态的深度与广度”展开——本质上,这是AI时代操作系统的雏形之争。
豆包目前的优势在于“广度”:通过字节系产品矩阵覆盖了办公、创作、社交、娱乐等多个场景。但挑战也同样明显:在垂直行业的深度解决方案上,仍有大量空白。这正是下一阶段的竞争焦点:通用大模型平台如何与垂直领域专业服务商协同,形成“基础模型+行业插件”的生态体系。
豆包百万亿级Token的深层意义,或许不在于具体数字是否准确,而在于 “用得起、用得好的AI时代真的来了”。
三年前,人们讨论AI时还在问:“它能做什么?”今天,在豆包等产品的推动下,问题变成了:“我该用它来做什么?”
价格门槛的降低——每百万Token输入仅3.2元;使用门槛的消失——深度集成于日常工具;价值门槛的突破——从聊天到视频创作、从问答到智能体执行。这三个变化叠加,让AI不再是科技圈的自嗨,而是如同电力、互联网一样的基础设施。
日均120万亿Tokens,不仅意味着豆包已经成为中国AI领域调用量最大、覆盖最广的大模型之一,更意味着它正在成为AI时代的“水电煤”——默默支撑着无数应用和服务,让AI真正变得无处不在。
120万亿Token背后,是一场刚刚开始的战争。而战争的胜负手,或许不在于谁的技术参数更漂亮,而在于谁的模型,真正被更多人、更多场景、更高频率地使用。
毕竟,在AI的世界里,被需要,才是最大的价值。









